Data model¶
The data model implemented in this package is summarized in the following figure:
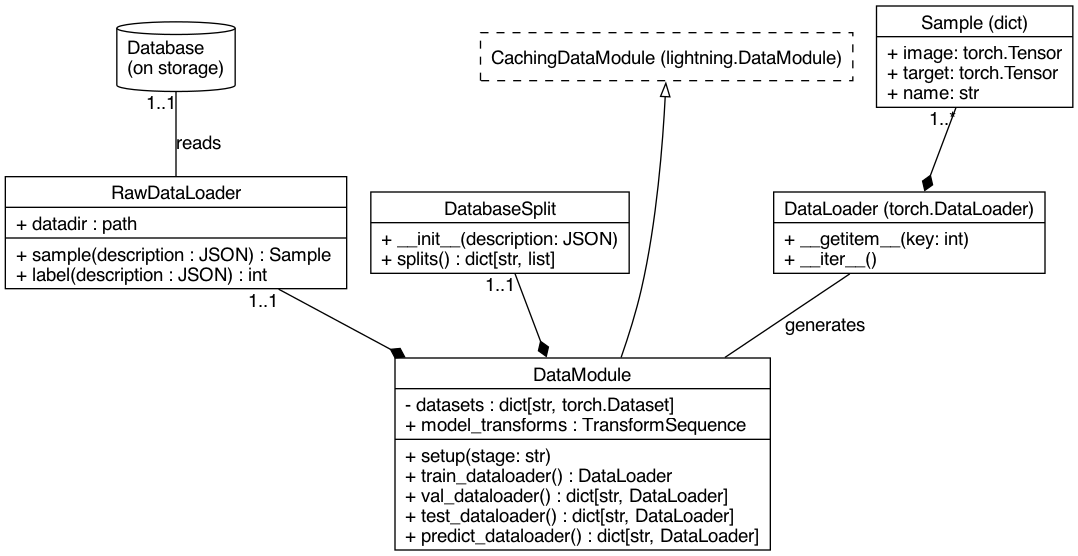
Each of the elements is described next.
Database¶
Data that is downloaded from a data provider, and contains samples in their raw
data format. The database may contain both data and metadata, and is supposed
to exist on disk (or any other storage device) in an arbitrary location that is
user-configurable, in the user environment. For example, databases 1 and 2 for
user A may be under /home/user-a/databases/database-1 and
/home/user-a/databases/database-2, while for user B, they may sit in
/groups/medical-data/DatabaseOne and /groups/medical-data/DatabaseTwo.
Sample¶
The in-memory representation of the raw database Sample. It is specified
as a dictionary containing at least the following keys:
image(torch.Tensor): the image to be analysedtarget(torch.Tensor): the target for the current taskname(str): a unique name for this sample
Optionally, depending on the task, the following keys may also be present:
mask(torch.Tensor): an inclusion mask for the input image and targets. If set, then it is used to evaluate errors only within the masked area.
RawDataLoader¶
A callable object that allows one to load the raw data and associated metadata,
to create a in-memory Sample representation. Concrete RawDataLoaders
are typically database-specific due to raw data and metadata encoding varying
quite a lot on different databases. RawDataLoaders may also embed various
pre-processing transformations to render data readily usable such as
pre-cropping of black pixel areas, or 16-bit to 8-bit auto-level conversion.
TransformSequence¶
A sequence of callables that allows one to transform torch.Tensor
objects into other torch.Tensor objects, typically to crop, resize,
convert color-spaces, and the such on raw-data. TransformSequences are used in
two main parts of this library: to power raw-data loading and transformations
required to fit data into a model (e.g. ensuring images are grayscale or
resized to a certain size), and to implement data-augmentations for
training-time usage.
DatabaseSplit¶
A dictionary-like object that represents an organization of the available raw
data in the database to perform an evaluation protocol (e.g. train, validation,
test) through datasets (or subsets). It is represented as dictionary mapping
dataset names to lists of “raw-data” Sample representations, which vary in
format depending on Database metadata availability. RawDataLoaders receive
this raw representations and can convert these to in-memory Samples. The
mednet.data.split.JSONDatabaseSplit is concrete example of a
DatabaseSplit implementation that can read the split definition from JSON
files, and is thoroughly at the library to represent the various database
splits supported.
ConcatDatabaseSplit¶
An extension of a DatabaseSplit, in which the split can be formed by
reusing various other DatabaseSplits to construct a new evaluation
protocol. Examples of this are cross-database tests, or the construction of
multi-Database training and validation subsets.
Dataset¶
An iterable object over in-memory Samples, inherited from the
torch.utils.data.Dataset. A Dataset in this framework may be
completely cached in memory, or have in-memory representation of Samples
loaded on demand. After data loading, Datasets can optionally apply a
TransformSequence, composed of pre-processing steps defined on a per-model
level before optionally caching in-memory Sample representations. The “raw”
representation of a Dataset are the split dictionary values (ie. not the
keys).
DataModule¶
A DataModule aggregates DatabaseSplits and RawDataLoaders to
provide lightning a known-interface to the complete evaluation protocol (train,
validation, prediction and testing) required for a full experiment to take
place. It automates control over data loading parallelisation and caching
inside the framework, providing final access to readily-usable pytorch
DataLoaders.